How to Create a Custom Import Method
DataGraph can automatically understand files coming from various platforms and using various separators (tab, comma, space delimited, etc.). In some cases, you may have more complicated data to import or you may only want to import a portion of data from a file. Rather than depend on other tools to manipulate your data into the appropriate format, you can use the Import Special method to define rules for how to import records from a file.
The DataGraph interface for creating custom import methods is called Import Special. When you create an import method, you can save the method to use on other files of the same format.
Key Features
The Import Special method requires you to specify the structure of the data. The methods you create are saved and can be shared between files.
Some key features of the method are:
- Preview results before importing.
- Specify columns to import.
- Specify the column type (number, text or date).
- Use multiple column separators.
- Use custom separators and keywords.
- Skip over lines.
- Have automatic substitutions during import.
- Include/Exclude rows based on a mask.
- Import directly from compressed gzip files (i.e., .gz ending).
- Import/Append data from multiple files at the same time.
You can even create a custom parser that will be applied automatically for files with a particular extension. Once created, files of that type can be imported using drag and drop importing.
Import Special Interface
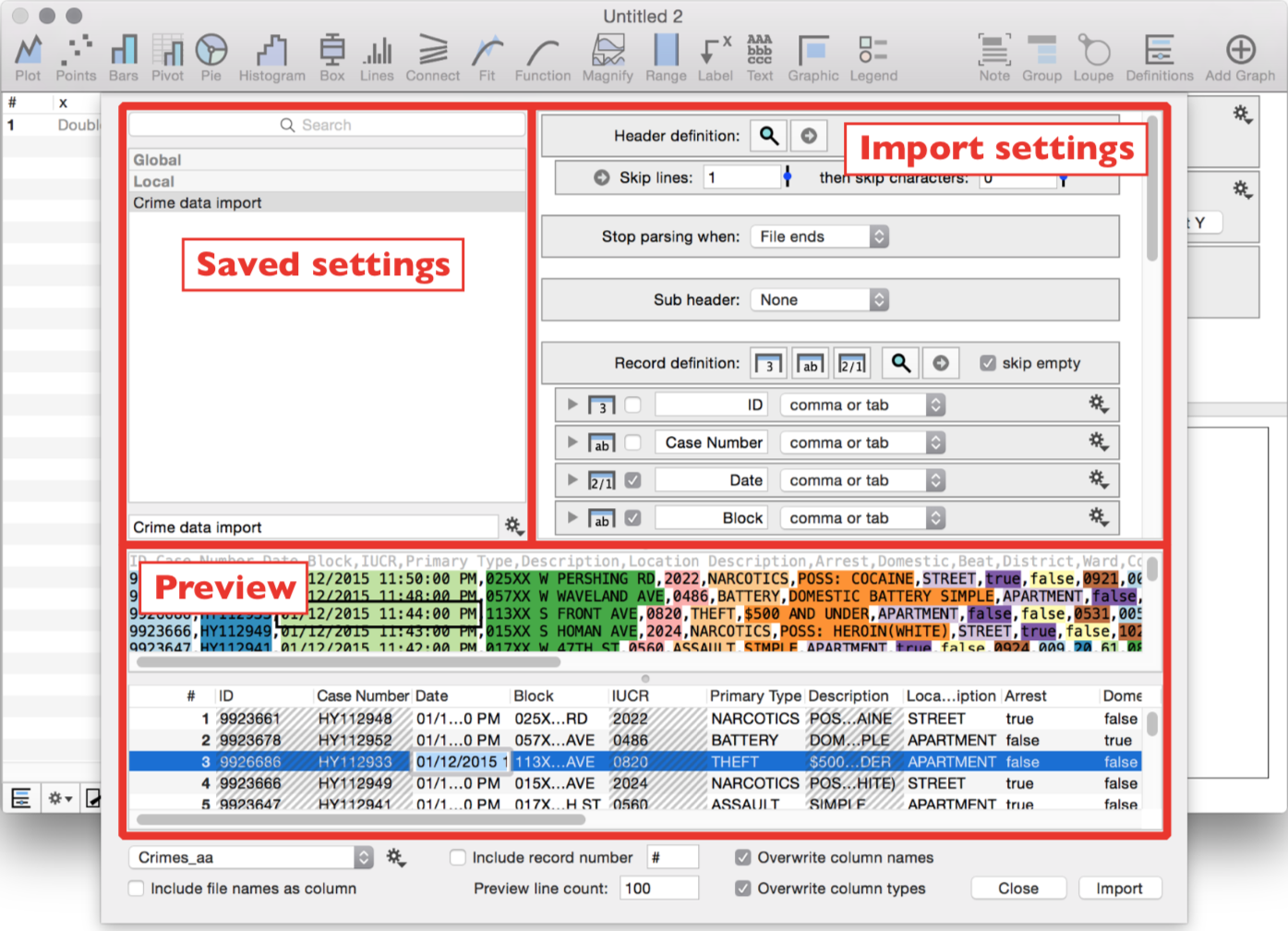
Below is the Import Special dialog box used to define the import settings for a given file or set of files.
- Import Settings: At the top right hand side, the import settings or rules are specified.
- Preview: At the bottom of the screen, you see a live preview. The top half of the preview shows the structure of the input data. The bottom of the preview shows how the data will be imported, based on the settings.
- Saved Settings: On the left hand side, the import settings are saved inside the DataGraph file. You can move the saved settings to a global list, such that you can use them in different DataGraph files.
NOTE: Import Special can be easily customized and not every setting or combinations of settings can be shown here. To further understand Import Special explore the settings and use the forum to submit questions.
How to Start
You can access the Import Special method from the Data menu.
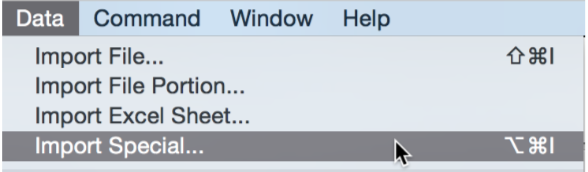
After you select Import Special, you must specify one or more files to import using the standard open dialog. Once you have selected the files and hit Open, the Import Special dialog opens.
In the lower left corner, the first file you selected is shown. You can access a list of all the files you selected using the drop-down menu.
Parsing a Stream of Data
The Import Special method is essential a way to read through a text file systematically from left to right and line by line, using rules to interpret the structure of the data, also referred to as parsing a stream of data.
The rules for parsing a file are defined in the import settings shown below.
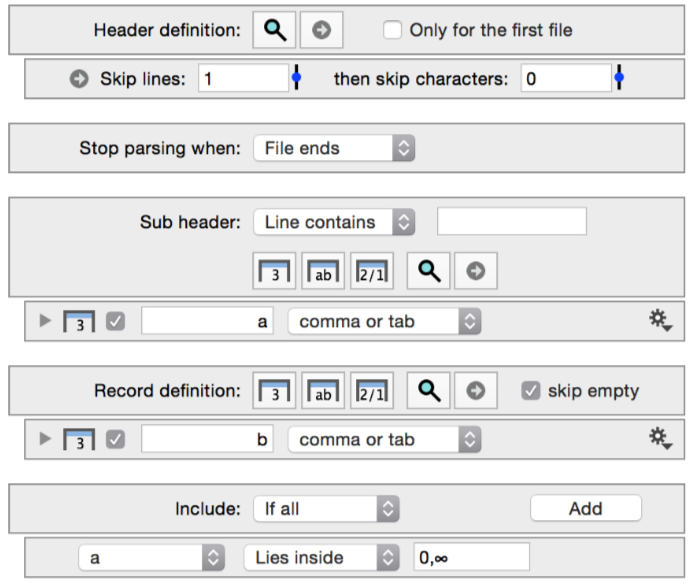
- Header definition: If there is a header defined, follow those steps to advance through the file to find a starting point. Data prior to the header is ignored.
- Stop parsing when: Check to see if the parser should be stopped.
- Sub header: Check to see whether or not the current line is the start of a sub header, if so read that in and go back to step 2.
- Record definition: Follow the record definition rules until you either hit a new line or you have gone through all of the record definition steps. Make sure that the focus moves onto the next line.
- Include: Check to see whether or not the line should be included according to any masks, if so add that record to the table.
- Go back to step 2.
Header definition
To define a header, you can either specify the number of lines in a file to skip before the data begins or search for a particular string to identify a header.
Stop parsing when
By default, this setting tells the parser to stop at the end of the file; however, if there is information at the end of a file that you do not want to import you can specify a string or numerical value to trigger the end of parsing.
Sub header
Data files that come from instrumentation can often contain sections or data with sub headers in between. The Sub header setting allows you to set up a parser that can identify the location of a sub header and can pull information from the sub header itself to put in a column entry.
Record definition
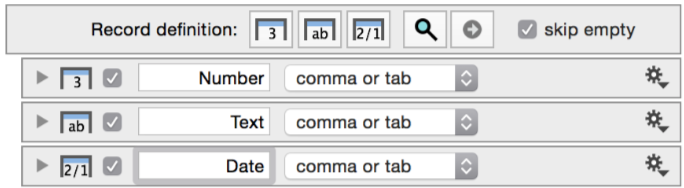
Most of the detail of how to parse though a file is located in the Record definition settings. Here you specify each column of data by the data type.
When you click one of the column icons, you add either a number, text, or date column, as shown below.
For each column of data you want to import, you also need to specify what determines the end of the column entry. Use the drop down menu to specify the desired method.
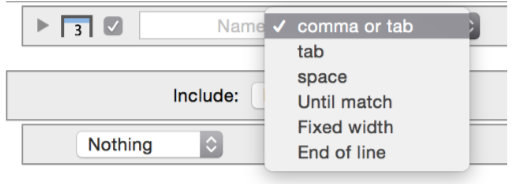
The ‘Until match’ option searches for a given text, and this does not have to be a single character. You can choose if the parser should stay at the beginning of what is found or skip over it and continue on the other side.
The ‘Fixed width’ option is for cases where the text is aligned by using spaces. This is very common when data files are created by a Fortran program.
The ‘End of Line’ option is used when the entry is ended by a new line and the next line is the next entry and not a new record. The new line character at the end is ignored, but the focus point goes to the next line in the file without viewing it as the end of the current record.
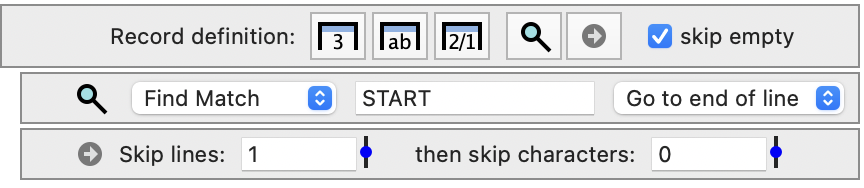
Searching and Skipping
In some files, data is separated by a unimportant text descriptions. You can use the search and skip methods to skip ahead in the text file. The search method will skip over lines and where the parsing resumes (focus point) is then adjusted by the menu to the right of the text field.
Include
The Include setting filters out specific rows of data to either include or exclude as the parser moves through the file. This works similar to other masks that are used in commands from within DataGraph.
For example, here only records would be included when the column ‘Data’ equals 1. You can also have multiple criteria.
