DataTask
ImageTank has two main ways to create and run external programs. One is the Action and the other a Task. The difference between them is that an Action runs automatically when you change the input and a Task you have to start by clicking a Run button. The action runs and then outputs a single variable, but the Task can run multiple variables as well as a sequence of variables.
Both of those methods are easiest to use when the execution time is relatively short, since you have to wait for the execution to finish. For cases where the execution takes a lot longer, for example because you are running a large number of tasks, a task that takes a long time or both. This is what the DataTask mechanism is created for. It allows you to set up a task that is run separate from ImageTank and the result then opened back and analyzed/viewed in ImageTank.
Big Picture
There are three distinct steps. You set up a job ticket, perform the calculations and then load in the result.
Set up a DataTask
Typically you start by running a reduced problem as either an Action or Task. From the gear menu you select the Create DataTask output entry to create an object that is connected to the same Xcode project and initially copies all of the input settings.

This is a different type of object. It is a type of Output object. You still have a link to the Xcode Project, but there is no debug feature or way to change the underlying project.

Once you are ready, click on the Create button, select a location for the job ticket and hit save. This will compute all of the input and bring you automatically to the next step.
Run a DataTask
When you save a DataTask, what you create is something that looks like a file in the Finder but is technically a package. A package is a folder that you can peek into either in the Finder or terminal. What ImageTank created was a package where every input is a separate folder. Initially only the input is stored in that folder. ImageTank automatically opens this file in the DataTask application that is on the same disk image as ImageTank.
By using a separate application you don’t have to keep ImageTank running for this step. In this application you have two choices. You can ask DataTask to run the specified task on your machine or a remote machine.
If you use the remote option DataTask will transfer the input over, copy the source code over as well and compile your program on the remote machine. If DataTask finds a supported load sharing program on that remote machine (currently Slurm) it will automatically submit your tasks to the job queue, otherwise it will use all of the available cores on that machine to run the tasks.
DataTask will then download the results back onto your machine. This will require DataTask to be running, but you can close the task file or quit DataTask and the next time you open the file DataTask will resume the download. All communication is done through a ssh connection.
View a DataTask
At any point you can open the DataTask “job ticket” in ImageTank. Just drag the file into the object list.
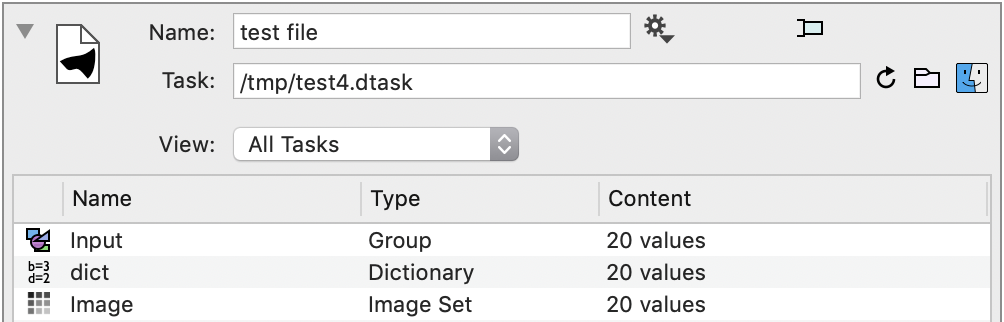
This views the entire job ticket as a single Data File object. You can view the results from all the individual runs or select a specific run. It combines the input and output into a single view.