Possible bug or my misunderstanding of exponential fit
Welcome to our Forums › Product Development › Bug reports › Possible bug or my misunderstanding of exponential fit
- This topic has 4 replies, 2 voices, and was last updated 2 years, 1 month ago by
 dgteam.
dgteam.
-
AuthorPosts
-
February 23, 2022 at 11:57 pm #8352
pharmpk
ParticipantHi
I was checking numbers etc. after getting the kel to half-life issue worked out and found a possible bug.
If I do an arbitrary fit of time-concentration I get a different power/slope than when I do a linear fit of time-log(concentration). The second version is the same as the answer I get with Numbers, where I have to take the log(base e) first. Weighting is Uniform. Weighting by log(Conc) makes a change but doesn’t ‘fix’ the issue. Not a big difference but could be larger with other data. Am I choosing the wrong weight? Thanks, David
Follow-up. Now that I can extract the Half-life for a label I thought I should look at an exponential fit of the original data. I get the ‘correct’ slope/power. Maybe the exp function has a problem? Or I’m misunderstanding the weights in this context.

Exponential fit
 February 24, 2022 at 7:18 pm #8435
February 24, 2022 at 7:18 pm #8435 dgteamModerator
dgteamModeratorFor the Arbitrary Fit, try changing the menu to the right of the Function form entry box, from ‘Linear’ to ‘Logarithmic’, you will get the same solution as the Exponential Fit.

We realized this was not well documented, in terms of what that option really means so we added more detail to the Fit command documentation on-line. As described on that page, the Linear option results in the absolute errors being minimized, while Logarithmic minimizes the relative errors.
By using the log transformation, the Exponential Fit is minimizing the relative error. So changing Arbitrary Fit to Logarithmic should result in the same output.
Using relative errors can greatly improve fit results when you have data that spans many orders of magnitude, ensuring that values are well fit throughout the data. In fact, the arbitrary fit may fail using the Linear option when the data has a wide range. You can always test out the difference by examining the residuals, which can be extracted using the gear menu on the command.
So you could use either one, but the Exponential is likely to perform better since you don’t have to worry about providing a good initial guess.
Does this help?
February 24, 2022 at 11:25 pm #8439ParticipantThanks, this helps. I’m still working through the weighting functions. I’ve always thought relative weight would be equivalent to 1/(y*y) but that doesn’t seem to work.
Do the residual plots show the weight residual when appropriate on the y axis?
February 25, 2022 at 7:24 pm #8447dgteamModeratorSee if this helps …
You can chose any column to use for the weight, but the values in the column are used directly. To use a weight derived from one of the data columns, calculate the values in a column first. Then select that column.
Here is an example before the weight is applied (weight = ‘Uniform’). You can expand the Residuals section to view a plot of the residuals.
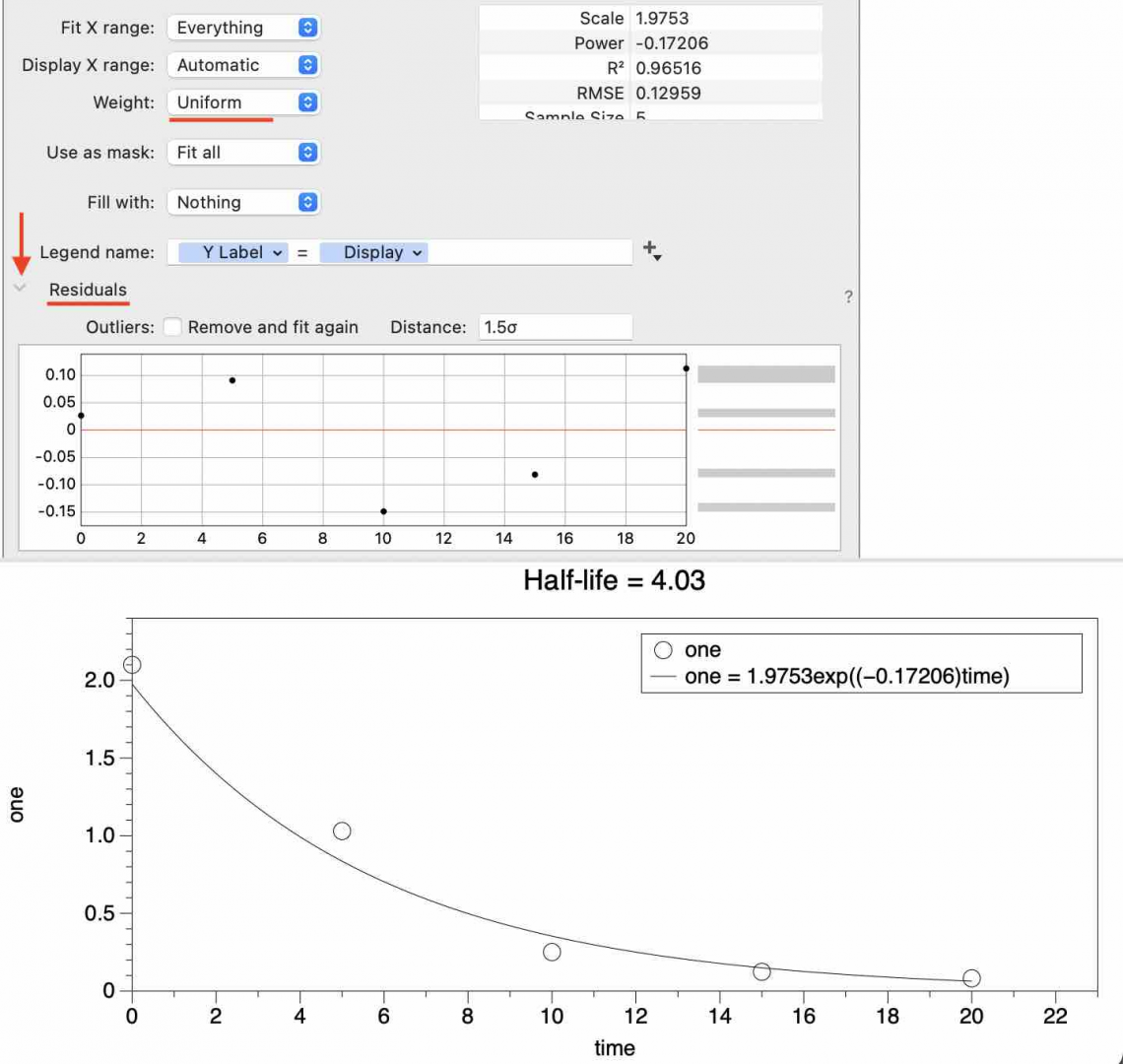
Here the weight function is calculated using an Expression column.

Then the expression column is chosen for the weights. You can see this has a dramatic impact on the plot as the larger numbers have very little impact now on the output. The points further on the x axis are closer to the fitted line, since they are heavily weighted.
 February 25, 2022 at 7:33 pm #8448dgteamModerator
February 25, 2022 at 7:33 pm #8448dgteamModeratorHere is the graph with the y scale set to logarithmic. The weights are applied to the log values. So when you view on a log scale, you can really see the impact of the weights here. The small values are fit very well but the larger values have much less impact, given the choice of weights.

-
AuthorPosts
- You must be logged in to reply to this topic.
Welcome to our Forums › Product Development › Bug reports › Possible bug or my misunderstanding of exponential fit